最近 TCP BBR congestion control comes to GCP – your Internet just got faster が話題になっていた.しかし,この記事を読んだ時点での自分の BBR についての知識は,「既存のものよりいい感じにしてくれる輻輳制御」ぐらいだった.これではまずいということで,BBR とはなんなのかについて,既存の輻輳制御にも触れながら,元の論文1 をメインにまとめた.自分が理解するための文書であるが,一応としての想定読者は,TCP が輻輳制御を行っていることを知っているぐらいの人である.TCP については,拙著の TCP/IP とパフォーマンス に短くまとめてあるので参照できる.
免責事項:
TCP を深く研究しているわけではなく,間違いを記述している可能性があります.コメントで教えていただけると助かります.
概要
BBR (Bottleneck Bandwidth and Round-trip propagation time) とは,Google が開発した新たな TCP 輻輳制御アルゴリズム.2016年9月に Linux Kernel に取り込まれ,論文は2017年2月に公開された. 既存の輻輳制御とは異なる輻輳検知,観測と推定をループするシステムモデルのアプローチにより,現代のネットワーク環境において高スループット,低レイテンシを発揮する.
背景
今日,Linux の TCP 輻輳アルゴリズムとして広く用いられているのは CUBIC2 であるが,loss-based (パケットロスを輻輳の判断に用いる) の原理自体は 1970 年代の TCP の誕生から変わっていない.しかし,ネットワークやスイッチの進化により,輻輳を回避するためのこの方式が Bufferbloat というパフォーマンス問題を引き起こすようになった.Bufferbloat は,本質的には Loss-based 輻輳制御アルゴリズムの性能限界を示していた.輻輳を回避しながらも,最大スループットと最小 RTT の達成を目標として設計されたのが BBR である.
Bufferbloat
Bufferbloat とは,非対称な帯域幅のリンクに挟まれたスイッチが引き起こすキューイング遅延による, End-to-End のレイテンシ増加のことをいう. 実際の “bloat” (むくみ) は,大きい帯域幅から小さい帯域幅へ向かうときに起こる3. 分かりやすい例として,以下の (極端な) last mile で考える.Router にはパケットを貯める送信 FIFO バッファ (以降 bottleneck queue とも書く)がある.
Sender ---- 1 [Gbps] ----> Router ---- 1 [Mbps] ----> Receiver
( TX buffer )Sender-Router 間のリンクは太く,Router-Receiver 間のリンクは細いため,Router がパケットを送信する速度より,パケットを受信する速度のほうが速く,バッファにパケットが貯まる.1つの TCP 接続だけがこのネットワークを利用しているならば,そこまで問題にならないが,ここで別の VoIP 接続 (latency-sensitive) があったとする.すると,VoIP パケットはバッファのキューイング遅延の影響を大きく受け,VoIP の体験は著しく悪化するといったことが起こる.
根本的な原因は,ネットワークに関する性能が低かった 1980 年代に開発された輻輳制御アルゴリズムでは,現在のネットワーク環境 (高速・長距離な伝送路,小さいバッファを持つコモディティスイッチ) で本来出せるべき性能が出せないことである.
TCP のモデル
TCP は,End-to-End のプロトコルであるため,End-to-End の経路上で実際に使うリンクの数や,それぞれのリンクの速度にかかわらず,TCP からは結局論理的な1つのリンクに見えるにすぎない.そのため,bottleneck が大きく意味を持つ.bottleneck は,接続の転送レート (delivery rate) [bps] を決定し,また慢性的に溜まりがちなパケットバッファの存在位置を決定する.TCP のパフォーマンスは,次の2つによって制約される.
- RTprop (Round-Trip propagation time): 往復伝搬遅延 (キューイング遅延,処理遅延を抜いた RTT)
- BtlBw (Bottleneck Bandwidth): 経路中最も小さい帯域幅
往復経路を1本の物理的なパイプに例えると,RTprop がパイプの長さ,BtlBw は最も小さい直径にあたる.任意の時刻にパイプに入れることができるデータ量の最大値は,BtwBw * RTprop で表現でき,これは BDP (Bandwidth-Delay Product: 帯域幅遅延積) としても知られる.
送信したが ACK が帰っていないデータのことを “inflight” (なデータ) と表現する.inflight と BDP の大小関係によって,パフォーマンスは次のように変化する.
-
delivery rate:
-
inflight < BDP
inflight を増加させれば delivery rate は増加する. -
inflight => BDP
delivery rate は最大となる.パイプから溢れたデータはバッファとなり,すなわちinflight - BDP が bottleneck queue となる. -
inflight > BDP + buffer size
バッファから溢れたパケットは破棄される.ここが CUBIC (loss-based) で輻輳を検知するポイントである.
-
-
RTT:
-
inflight < BDP
RTprop を下回ることはない.RTT ~ RTprop である. -
inflight => BDP
bottleneck queue のキューイング遅延分だけ RTprop よりも増加する. -
inflight > BDP + buffer size
キューイング遅延は一定となり,RTT は最大値になる.
-
上記を表したのが次の図である.
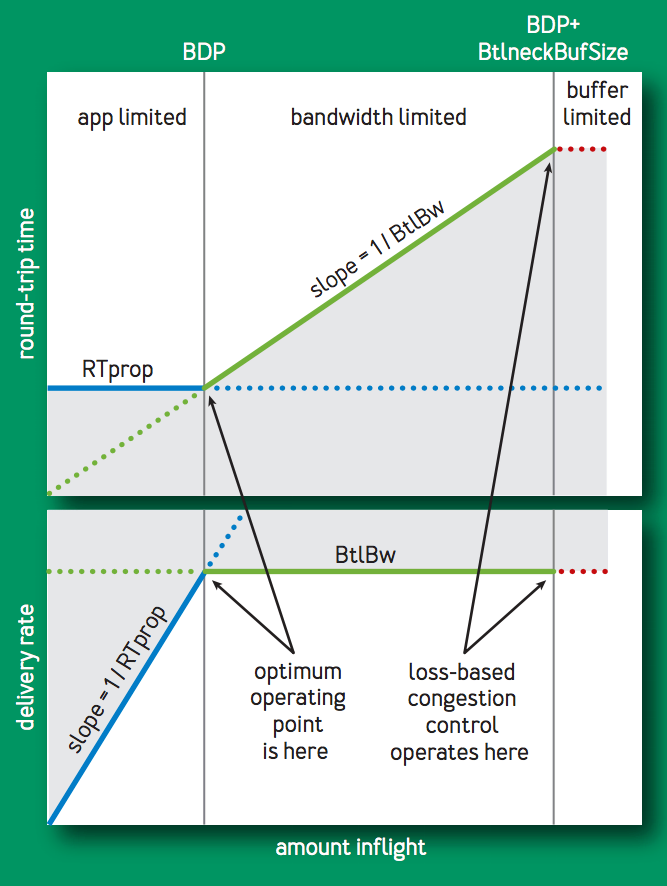
delivery rate と RTT の2つの観点から,inflight == BDP のポイントが最適な性能であることが見て取れる.このポイントの時,Kleinrock による輻輳モデル[^4]では,個々のコネクションだけでなくネットワーク全体で,最大の転送レートかつ最小の遅延,最小のパケットロスの性能があることが示されている. しかし,Jeffe は同時期に,このポイントに収束する分散アルゴリズムは作成不可能であることを示した[^5].なぜなら,delivery rate と RTT を同時に測定することは不可能だからである.
一方で,Jeffe の結果は,例えば測定された RTT が増加した場合,それが経路長の変化によるものなのか,BtlBw の減少によるものなのかなどの,測定の曖昧さに依存する.単独の測定値でポイントを見積もることは不可能だが,時間の経過とともにコネクションの振る舞いはより明確になり,この曖昧さを解消するように見積もりができる可能性があった.Google の研究チームは,長きに渡って世界中の TCP コネクションを観察し続け,この可能性に着目した.
関連手法
基本的な輻輳制御手法について簡単に書く. End-to-End の輻輳制御は,次の3種類に分類される4.
- loss-based
- delay-based
- hybrid (loss-based + delay-based)
ただし,hybrid はここでは紹介しない.
loss-based
送信レートを増加させていき,スイッチのバッファ溢れによってパケットが廃棄される状態を輻輳とみなし,送信レートを制御する手法.
Tahoe
BSD 4.3 の輻輳制御である.後に Reno へと改良される.ちなみに,Tahoe, Reno の名前は,ネバダ州 Reno city の Tahoe 湖から来ているらしい5.コネクション確立後,cwnd の値を 1 から指数的に増加させ (スロースタート), 輻輳を検知すると cwnd を 1 に戻す.このときの cwnd / 2 の値を閾値 (ssthresh) として記憶する.その後は,sshtresh まではスロースタートし,以降は線形に cwnd を増加させ,輻輳を検知したら cwnd を 1 に戻すルーチンを繰り返す.TCP Tahoe のウインドウ増加関数を次の図に示す6.
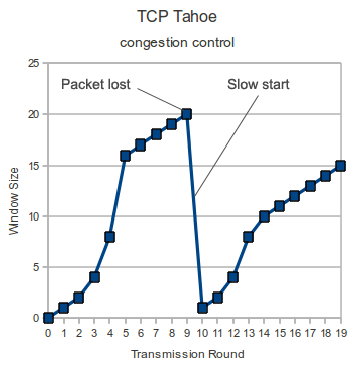
Scenario in TCP Tahoe, where congestion control reacts to a timed out ACK with a slow restart. (quoted from 8 )
Reno
Tahoe を改良した手法で,輻輳を検知した時 cwnd を 1 まで落とすのではなく,sshtresh に落とす.過剰なウインドウサイズの減少をやめることで,スループットが増加した.TCP Reno のウインドウ増加関数を次の図1に示す.
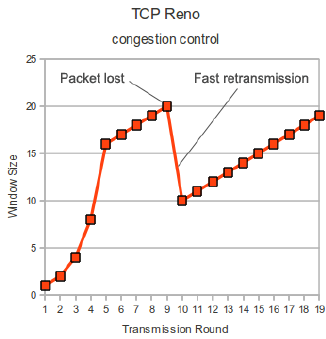
Scenario in TCP Reno, where congestion control reacts with fast retransmission as response to three duplicate ACKs. (quoted from 8 )
BIC
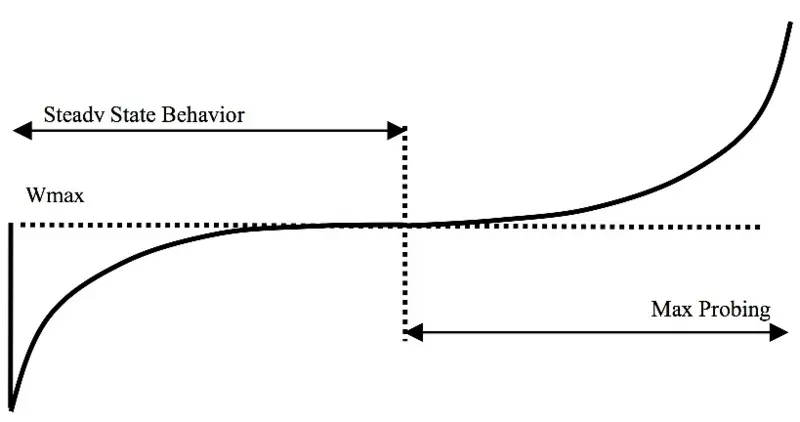
BIC-TCP (Binary Increase Congestion Control) は,パケットロスの発生を平衡点とみなし,次の平衡点を探索するように動作する.パケットロス時点での cwnd を Wmax として記憶し,cwnd を減少させる.その後線形に増加させた (Additive Increase) 後,指数的に増加させる (Binary Search).平衡点以降も,パケットロスが発生させるまでは cwnd を増加させる (Max Probing).BIC-TCP ウインドウ増加関数の図を以下に示す.
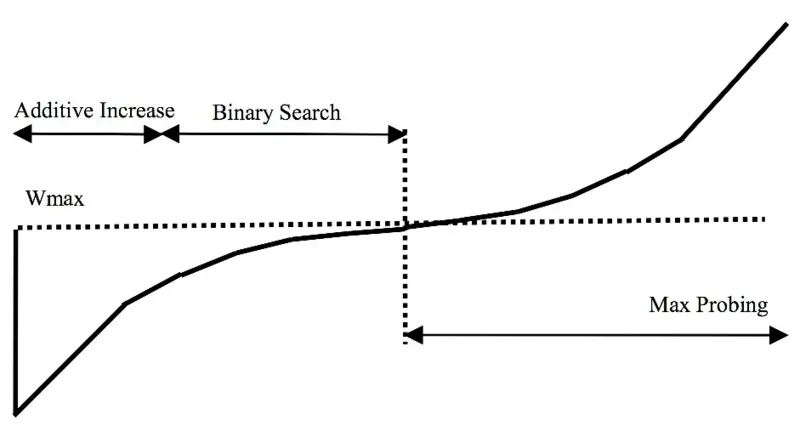
CUBIC
CUBIC-TCP は,BIC-TCP のウインドウ関数を三次関数で簡略化近似したものである. Linux 2.6.19 以降7,Linux のデフォルト輻輳制御である.
delay-based
各パケットの RTT を監視し,スイッチでのキューイング遅延の増大による RTT の増加を,輻輳の初期段階の指標として利用する手法6. delay-based による制御は,理想的に振る舞う限りはパケット廃棄が発生せず,かつ低遅延伝送が可能になるため,loss-based を凌ぐスループット効率の実現が示唆される8.
Vegas
バッファ内に数個のパケットを保持するようにウインドウサイズを調整する.現時点での RTT と,最小の RTT を用いて,実際のスループット (expected) と期待できるスループット (actual) を計算する. actual の方が expected より十分小さければ,cwnd をインクリメントする.逆に,actual の方が expected より十分大きければ,cwnd をデクリメントする,という戦略である.
提案手法
BBR は,経路を RTprop, BtlBw をパラメータとするパイプでモデル化し,パケットロスや過渡なキューイング遅延ではなく,“実際の輻輳” に反応する輻輳制御 (Congestion-based Congestion Control) であり,ネットワーク使用率を最大化し,bottleneck のバッファ長を最小化する.実際の輻輳とは,Kleinrock の輻輳モデルに基づく,経路で使用可能な容量をデータ容量が上回っている状態を指す.
大まかには,ACK を受け取る毎に,次の動作をする.
- 現在の RTT と delivery rate を測定
- RTprop と BtlBw を推定し,パイプモデルを作成:
- RTprop: windowed-min-filtered RTT (数十秒〜数分間隔のスライディング時間ウインドウにおける最小の RTT 測定値)
- BtlBw: windowed-max-filtered delivery rate (6 ~ 10 RTT 間隔のスライディング時間ウインドウにおける最大の delivery rate)
- pacing gain を決定し,cwnd に gain を適用
pacing gain は,BtlBw に対するデータ送信速度の比であり,BBR の学習能力の鍵となるものである.pacing gain が 1.0 より大きければ,inflight が増加し,いずれ delivery rate は BtlBw に収束する.反対に,1.0 より小さければ,inflight が減少し,RTT は RTprop 付近に収束する.
言葉を変えると,BBR は,pacing gain による,大きな帯域幅のテストと小さな RTT のテストを交互に行う連続的なプロービングステートマシンの実装である.windowed-max-filter によって自動で処理されるため,小さな帯域幅は確認する必要がない.同様に,windowed-min-filter が経路長の増加を自動的に処理するため,大きな RTT のテストも必要ない.
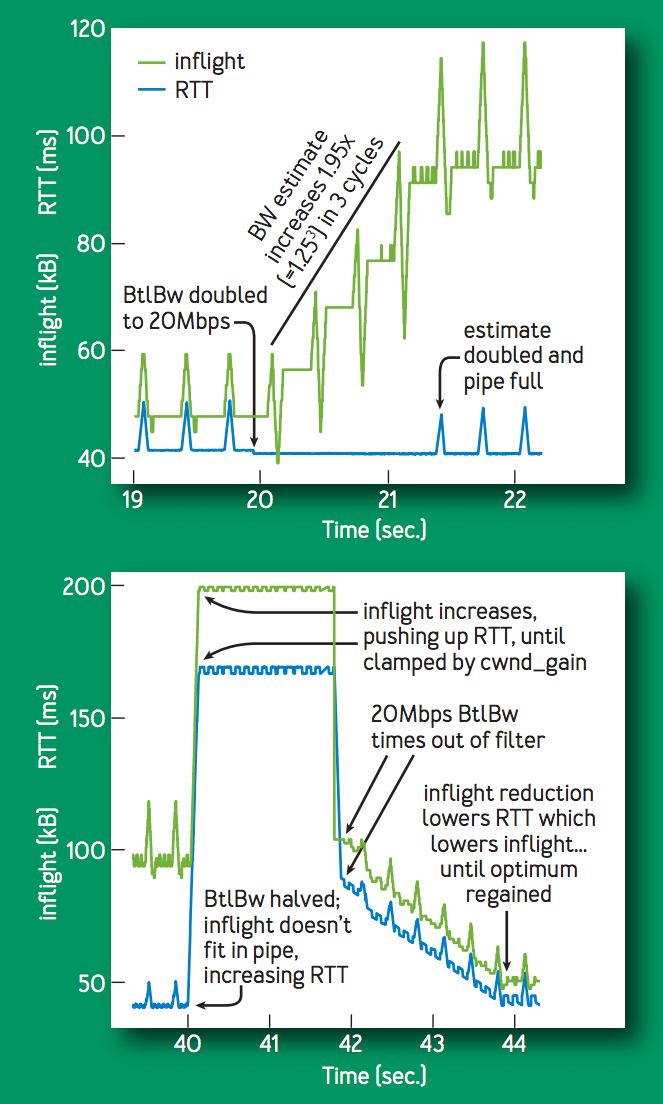
次の図は,BtlBw が 10 [Mbps], 40 [ms] のフローに対して, 20 秒後に BtlBw を 20 [Mbps] に急増させた場合と,その更に20秒後に 10 [Mbps] に急減させた場合の inflight, RTT の遷移である. BtlBw が増加すると,delivery rate が増加し,新たな windowed-max-filter の出力が増加し,pacing rate が増加する.したがって,pacing rate の倍数増加で新たな bottleneck rate へ収束する.逆に BtlBw が低下すると,バッファ長の増加によって inflight, RTT が増加する.20 [Mbps] の windowed-max-filter が時間経過によって失われると,delivery rate が低下する.その後は,RTT が低下しなくなるまで inflight を低下させるように pacing gain を変化させ制御する.
状態遷移モデル
BBR の実装は,4つの状態をとる次のダイアグラムで表される.
# https://github.com/torvalds/linux/blob/master/net/ipv4/tcp_bbr.c
|
V
+---> STARTUP ----+
| | |
| V |
| DRAIN ----+
| | |
| V |
+---> PROBE_BW ----+
| ^ | |
| | | |
| +----+ |
| |
+---- PROBE_RTT <--+STARTUP
初期状態である.素早く送信レートを上げるために,帯域幅のオーダー (数 bit から数 Gbit) で binary search する.転送レートの増加で送信レートを2倍にするために,2 / ln(2) の pacing gain を使用する.パイプがサチるまたはバッファがサチった場合,すなわち転送レートが増加しなくなったら DRAIN へ.
DRAIN
STARTUP の pacing gain の逆数を用いて,一杯になったバッファからパケットを減らす.そして,一度 inflight が BDP まで落ちると,BBR は定常状態となり,PROBE_BW に移行する.
PROBE_BW
BBR flow の大半がこの状態で安定する. この状態では,pacing gain を循環させる,gain cycling を行う.5/4, 3/4, 1, 1, 1, 1, 1, 1 の 8 相サイクルを使用する.各位相は通常,推定された RTprop の間持続する. この gain cycling は,1.0 より大きい pacing gain でより大きい帯域幅を調べ,その後 1.0 より小さい gain でバッファをドレインし,1.0 の gain によりバッファを短く保つ.
PROBE_RTT
推定 RTprop が 10 秒以上の場合,この状態に突入し,bottleneck queue をフラッシュする.具体的には,cwnd を非常に小さい値 (= 4) に減少させる.十分に長く待った後 (少なくとも 200[ms]), パイプが既にフルになっているかの推測に応じて,STARTUP または PROBE_BW に移行する.
評価
BBR の評価について簡単にまとめる.
BBR vs. CUBIC
同経路1セッションにおける BBR と CUBIC の比較.
スタートアップ時
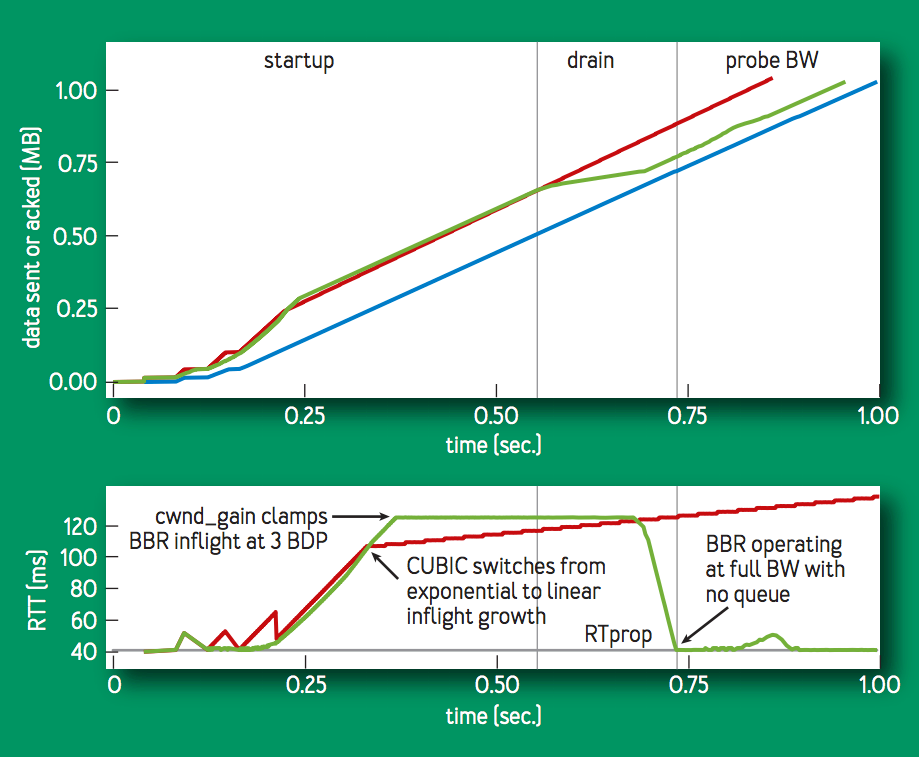
次の図の下のグラフは,BBR と CUBIC の RTT 推移の対比である. 最初のスロースタートの動作は似ているが,BBR はパイプをフルにしてからバッファをドレインするように動作するのに対し,CUBIC ではバッファを気にすることなく,パケットロスの発生または rwnd の制限まで inflight を線形に増加させる.CUBIC に対して, BBR は RTT を RTprop 付近に抑えつつ,CUBIC に近いスループットを出力している (上の図).
スタートアップ以後
CUBIC (赤線) は,バッファを埋め尽くした後,数秒ごとに 70% ~ 100% のバッファを使用するサイクルを繰り返す.BBR (緑線) は,基本的にはバッファの待ち行列なしに実行される.
Multiple BBR Flows
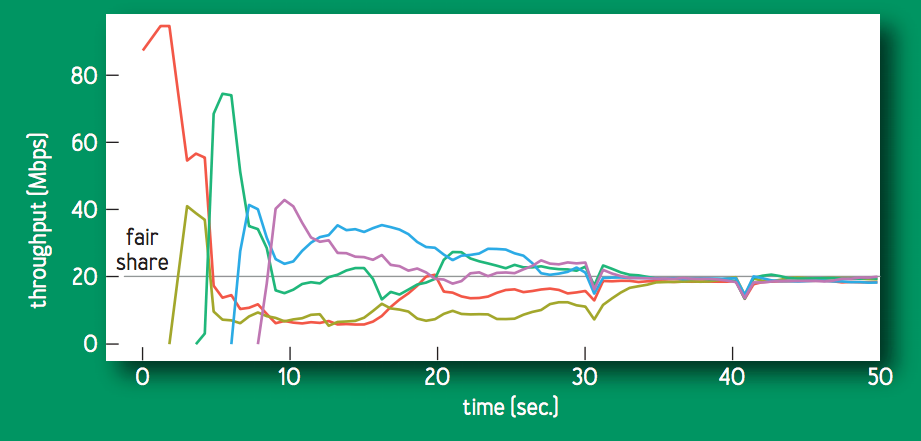
次の図は,100 [Mbps], 10 [ms] のボトルネックを共有する複数の BBR フローについて,個々のスループットが公平に収束する様子を示す.PROBE_BW の gain cycling によって,より大きなフローに対して,小さなフローに帯域を譲るように動作し,結果として個々のフローが公平なシェアを学習する.
PROBE_RTT は,公平性と安定性の両方の鍵となる.推定 RTprop が数秒以上更新されていない場合,PROBE_RTT 状態に遷移し,バッファから多くのパケットを排出するため,いくつかのフローでは推定 RTprop が更新される (新たな最小 RTT).
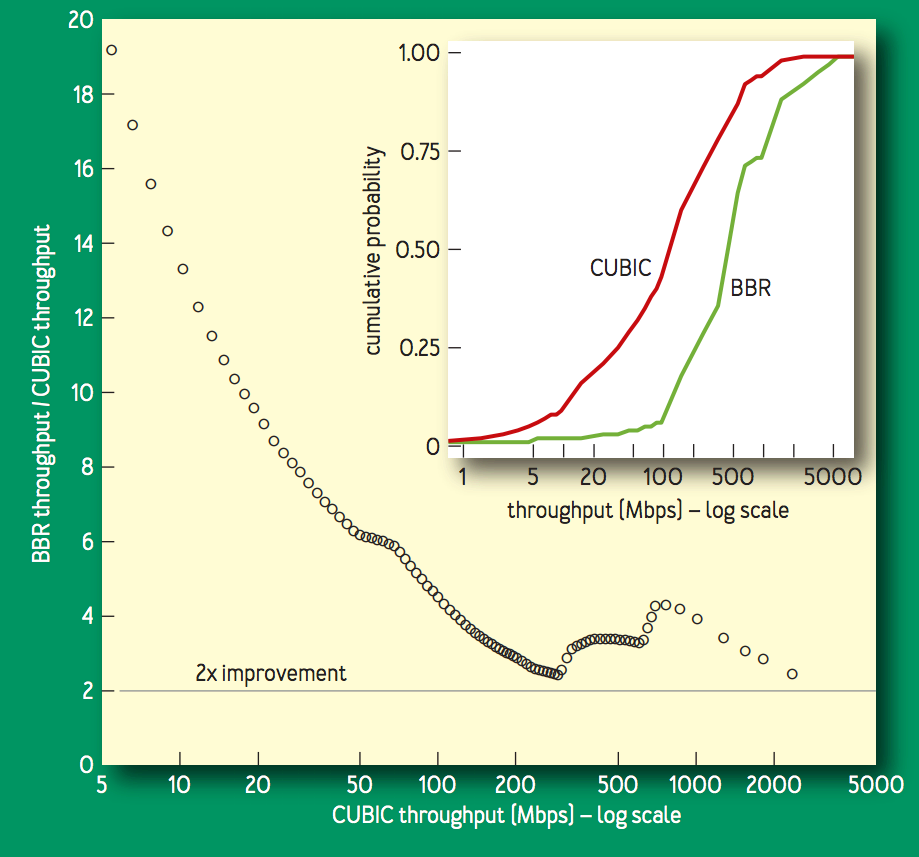
Google B4 WAN
B49 は,コモディティスイッチで構築された Google の高速 WAN である.2015 年に,B4 の輻輳制御を CUBIC から BBR に切り替え始め,2016 年以降は BBR が 100% デプロイされている.切り替え理由の1つを示す次の図は,毎分 8 [MB] のデータを送信する BBR と CUBIC のコネクション (北米,ヨーロッパ,アジア間で多数の B4 経路を経由する) のスループット比較である.BBR のスループットは CUBIC のものよりも常に2倍〜25倍であることを示している.
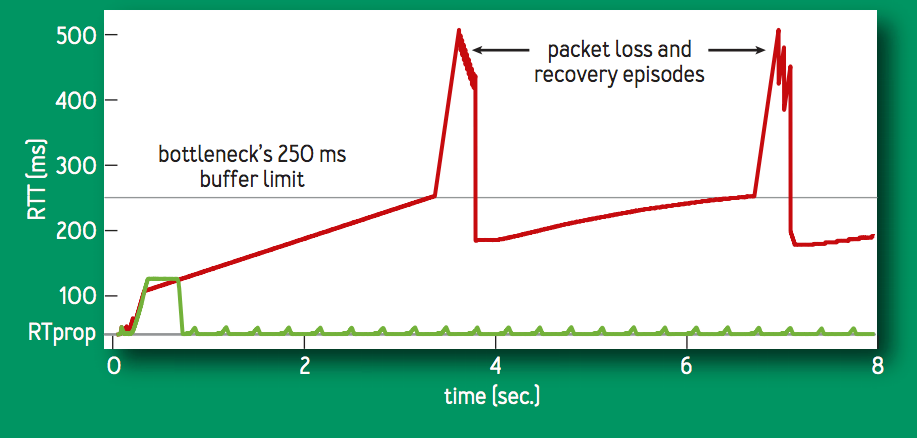
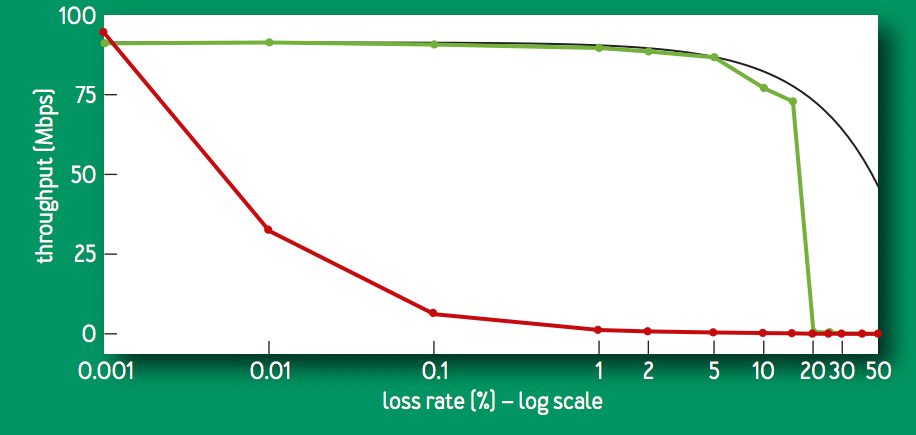
この大幅なスループットの改善は,BBR が loss-based ではないことが直接的に影響している.次の図は,100 [Mbps], 100 [ms] のリンクで,60秒間のフローに対するランダムパケットロス率と goodput (送信者から受信者に正常に伝送された実際のデータ量を示す計測値) の関係の比較である.CUBIC (赤色) は,0.1% の損失でスループットが 1/10 になってしまう一方,BBR (緑色) は 15% の損失までは 95% のスループットを維持する.
まとめ
BBR は,パケットロスやバッファ占有を輻輳検知に利用するのではなく,Kleinrock の輻輳モデルに基づく実際のネットワーク輻輳を検知するという点で新しい輻輳制御である.RTprop と BtlBw の2つの決定的なパラメータを同時に決定することは不可能な事実に対して,近年進化したシステムモデルと推定理論を用いて,パラメータを逐次的に観察して推定し,準最適に動作する.使用可能帯域を使い切りながらも,バッファ長を短く留めることにより,理論的に最も良いスループットと RTT の両方を達成する.
Google の広域 WAN に導入され,CUBIC と比較しスループットの大幅な向上を確認した.また,Google と YouTube の Web サーバにも導入されており,開発途上地域 (低品質のネットワーク) でレイテンシが劇的にされた.
Linux における BBR
Linux Kernel には,2016年9月に BBR の最初の実装が取り込まれ10,4.9 以降で有効化できる11.実際の手順などの詳細は Increase your Linux server Internet speed with TCP BBR congestion control で述べられており,ここでは記事の紹介に留める.
おわりに
BBR が既存の輻輳制御と根本的に何が異なっているのかが理解できた.また,TCP 関連を調べていたときに出会って,結局良くわからずじまいだった BDP の理解も深まったので良かった.
詳細なシステム制御モデルや,推定モデルは理解しきれなかったため述べていない.また興味が出たら調べたい.また,BBR と既存の輻輳制御との共存も調べきれていない.実はうまくいかないとも指摘されている12.
参考文献
Footnotes
-
Neal Cardwell, Yuchung Cheng, C. Stephen Gunn, Soheil Hassas Yeganeh, Van Jacobson, “BBR: Congestion Based Congestion Control,” Communications of the ACM, Vol. 60 No. 2, Pages 58-66, http://queue.acm.org/detail.cfm?id=3022184 ↩
-
Rhee, I. and L. Xu, “CUBIC: A new TCP-friendly high-speed TCP variant”, PFLDnet 2005, February 2005. ↩
-
長谷川剛, “インターネットの輻輳制御技術,” 生産と技術 第64巻, 第4号, p28-33, 2012, http://seisan.server-shared.com/644/644-28.pdf ↩
-
TCP congestion control - Wikipedia, https://en.wikipedia.org/wiki/TCP_congestion_control#TCP_Tahoe_and_Reno ↩
-
Runemalm, David & Sarwar, Dewan & Shalbaf, Maziar. (2017). Decreasing the Hybrid-ARQ bandwidth overhead through the Multiple Packet NAK (MPN) protocol., https://www.researchgate.net/publication/267554658_Decreasing_the_Hybrid-ARQ_bandwidth_overhead_through_the_Multiple_Packet_NAK_MPN_protocol ↩
-
“Linux 2 6 19,” https://kernelnewbies.org/Linux_2_6_19 ↩
-
甲藤二郎, 村瀬 勉, “2章 TCP (Transmission Control Protocol) の改善,” 電子情報通信学会 知識ベース『知識の森』, 3郡 コンピュータネットワーク > 4編 トランスポートサービス, http://www.ieice-hbkb.org/files/03/03gun_04hen_02.pdf ↩
-
Sushant Jain, Alok Kumar, Subhasree Mandal, Joon Ong, Leon Poutievski, Arjun Singh, Subbaiah Venkata, Jim Wanderer, Junlan Zhou, Min Zhu, Jon Zolla, Urs Hölzle, Stephen Stuart, and Amin Vahdat. 2013. B4: experience with a globally-deployed software defined wan. In Proceedings of the ACM SIGCOMM 2013 conference on SIGCOMM (SIGCOMM ‘13). ACM, New York, NY, USA, 3-14. DOI: http://dx.doi.org/10.1145/2486001.2486019 ↩
-
“tcp_bbr: add BBR congetsion control - Github: torvalds/linux,” https://github.com/torvalds/linux/commit/0f8782ea14974ce992618b55f0c041ef43ed0b78 ↩
-
“Linux 4.9,” https://kernelnewbies.org/Linux_4.9 ↩
-
Geoff Huston, “BBR, the new kid on the TCP block,” https://blog.apnic.net/2017/05/09/bbr-new-kid-tcp-block/ ↩